Tick位图索引
作为动态交换的第一步,我们需要实现一个tick索引。在上一个里程碑中,我们曾经在进行交换时计算目标tick:
function swap(address recipient, bytes calldata data)
public
returns (int256 amount0, int256 amount1)
{
int24 nextTick = 85184;
...
}
当在不同价格范围内提供流动性时,我们不能简单地计算目标tick。我们需要找到它。因此,我们需要索引所有有流动性的tick,然后使用这个索引来找到tick,以便为交换"注入"足够的流动性。在这一步中,我们将实现这样一个索引。
位图
位图是一种以紧凑方式索引数据的流行技术。位图简单来说就是一个以二进制系统表示的数字,例如31337是111101001101001。我们可以将其视为一个由零和一组成的数组,每个数字都有一个索引。然后我们说0表示标志未设置,1表示已设置。所以我们得到的是一个非常紧凑的索引标志数组:每个字节可以容纳8个标志。在Solidity中,我们可以有最多256位的整数,这意味着一个uint256可以保存256个标志。
Uniswap V3使用这种技术来存储已初始化tick的信息,即有一些流动性的tick。当标志设置为1时,tick有流动性;当标志未设置(0)时,tick未初始化。让我们看看实现。
TickBitmap合约
在池合约中,tick索引存储在一个状态变量中:
contract UniswapV3Pool {
using TickBitmap for mapping(int16 => uint256);
mapping(int16 => uint256) public tickBitmap;
...
}
这是一个映射,其中键是int16,值是字(uint256)。想象一个无限连续的由一和零组成的数组:

这个数组中的每个元素对应一个tick。为了在这个数组中导航,我们将其分解为字:长度为256位的子数组。要找到tick在这个数组中的位置,我们这样做:
function position(int24 tick) private pure returns (int16 wordPos, uint8 bitPos) {
wordPos = int16(tick >> 8);
bitPos = uint8(uint24(tick % 256));
}
也就是说:我们找到它的字位置,然后找到它在这个字中的位。>> 8等同于整数除以256。因此,字位置是tick索引除以256的整数部分,而位位置是余数。
作为例子,让我们计算我们其中一个tick的字和位位置:
tick = 85176
word_pos = tick >> 8 # or tick // 2**8
bit_pos = tick % 256
print(f"Word {word_pos}, bit {bit_pos}")
# Word 332, bit 184
翻转标志
当向池中添加流动性时,我们需要在位图中设置两个tick标志:一个用于下限tick,一个用于上限tick。我们在位图映射的flipTick方法中执行此操作:
function flipTick(
mapping(int16 => uint256) storage self,
int24 tick,
int24 tickSpacing
) internal {
require(tick % tickSpacing == 0); // ensure that the tick is spaced
(int16 wordPos, uint8 bitPos) = position(tick / tickSpacing);
uint256 mask = 1 << bitPos;
self[wordPos] ^= mask;
}
在本书的后面部分之前,
tickSpacing始终为1。请记住,这个值会影响哪些tick可以被初始化:当它等于1时,所有的tick都可以被翻转;当它被设置为不同的值时,只有可以被该值整除的tick才能被翻转。
在找到字位置和位位置后,我们需要制作一个掩码。掩码是一个在tick的位位置上设置了单个1标志的数字。要找到掩码,我们只需计算2**bit_pos(等同于1 << bit_pos):
mask = 2**bit_pos # or 1 << bit_pos
print(format(mask, '#0258b')) ↓ here
#0b0000000000000000000000000000000000000000000000000000000000000000000000010000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000
接下来,为了翻转一个标志,我们通过按位异或(bitwise XOR)将掩码应用到tick的字上:
word = (2**256) - 1 # set word to all ones
print(format(word ^ mask, '#0258b')) ↓ here
#0b1111111111111111111111111111111111111111111111111111111111111111111111101111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111
你会看到第184位(从右边开始数,从0开始)已经翻转为0。
如果一个位是零,它会将其设置为1:
word = 0
print(format(word ^ mask, '#0258b')) ↓ here
#0b0000000000000000000000000000000000000000000000000000000000000000000000010000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000
寻找下一个Tick
下一步是使用位图索引寻找有流动性的tick。
在进行交换时,我们需要找到当前tick之前或之后的有流动性的tick(即:在它的左边或右边)。在上一个里程碑中,我们曾经计算并硬编码它,但现在我们需要使用位图索引来找到这样的tick。我们将在TickBitmap.nextInitializedTickWithinOneWord函数中实现这一点。在这个函数中,我们需要实现两种场景:
-
当卖出代币(在我们的例子中是ETH)时,在当前tick的字中找到下一个初始化的tick,并且在当前tick的右边。
-
当卖出代币(在我们的例子中是USDC)时,在下一个(当前+1)tick的字中找到下一个初始化的tick,并且在当前tick的左边。
这对应于在任一方向进行交换时的价格变动:
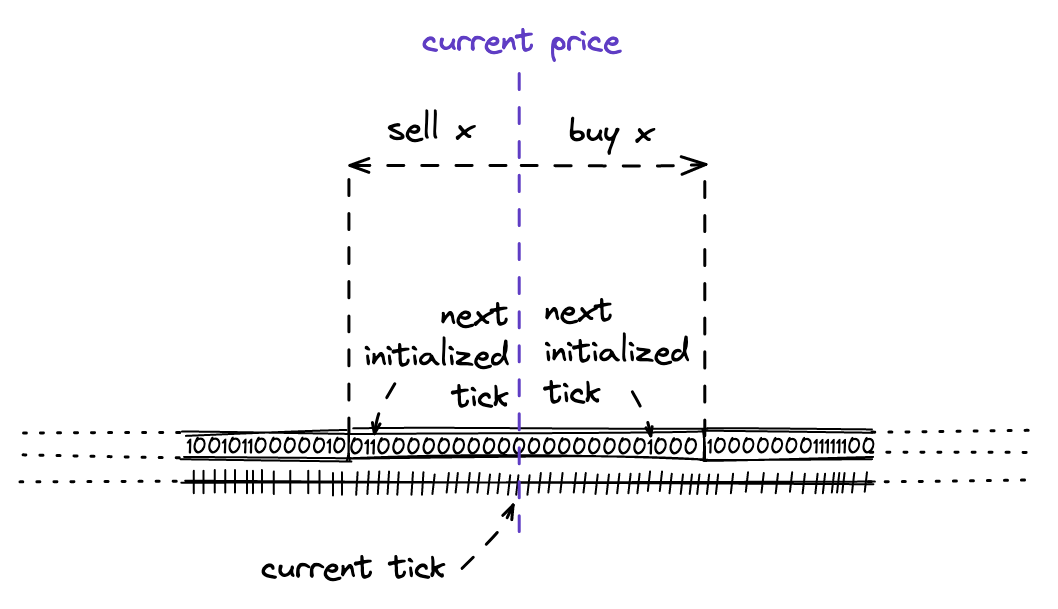
请注意,在代码中,方向是翻转的:当买入代币时,我们搜索当前tick左边的初始化tick;当卖出代币时,我们搜索右边的tick。但这只在一个字内是正确的;字是从左到右排序的。
当当前字中没有初始化的tick时,我们将在下一个循环周期中继续在相邻的字中搜索。
现在,让我们看看实现:
function nextInitializedTickWithinOneWord(
mapping(int16 => uint256) storage self,
int24 tick,
int24 tickSpacing,
bool lte
) internal view returns (int24 next, bool initialized) {
int24 compressed = tick / tickSpacing;
...
-
第一个参数使这个函数成为
mapping(int16 => uint256)的方法。 -
tick是当前的tick。 -
tickSpacing在我们开始在里程碑4中使用它之前始终为1。 -
lte是设置方向的标志。当为true时,我们正在卖出代币,并搜索当前tick右边的下一个初始化tick。当为false时,情况相反。lte等同于交换方向:当卖出代币时为true,否则为false。
if (lte) {
(int16 wordPos, uint8 bitPos) = position(compressed);
uint256 mask = (1 << bitPos) - 1 + (1 << bitPos);
uint256 masked = self[wordPos] & mask;
...
当卖出时,我们:
-
获取当前tick的字位置和位位置;
-
制作一个掩码,其中当前位位置右边的所有位(包括当前位)都是1(
mask全是1,其长度 =bitPos); -
将掩码应用到当前tick的字上。
...
initialized = masked != 0;
next = initialized
? (compressed - int24(uint24(bitPos - BitMath.mostSignificantBit(masked)))) * tickSpacing
: (compressed - int24(uint24(bitPos))) * tickSpacing;
...
接下来,如果masked中至少有一位被设置为1,则masked不会等于0。如果是这样,就存在一个初始化的tick;如果不是,则不存在(至少在当前字中不存在)。根据结果,我们要么返回下一个初始化tick的索引,要么返回下一个字中最左边的位——这将允许我们在另一个循环周期中搜索该字中的初始化tick。
...
} else {
(int16 wordPos, uint8 bitPos) = position(compressed + 1);
uint256 mask = ~((1 << bitPos) - 1);
uint256 masked = self[wordPos] & mask;
...
类似地,当卖出时,我们:
-
获取当前tick的字位置和位位置;
-
制作一个不同的掩码,其中当前tick位位置左边的所有位都是1,右边的所有位都是0;
-
将掩码应用到当前tick的字上。
同样,如果左边没有初始化的tick,则返回前一个字的最右边的位:
...
initialized = masked != 0;
// overflow/underflow is possible, but prevented externally by limiting both tickSpacing and tick
next = initialized
? (compressed + 1 + int24(uint24((BitMath.leastSignificantBit(masked) - bitPos)))) * tickSpacing
: (compressed + 1 + int24(uint24((type(uint8).max - bitPos)))) * tickSpacing;
}
就是这样!
正如你所看到的,nextInitializedTickWithinOneWord如果目标tick距离很远,并不会找到确切的tick——它的搜索范围是当前或下一个tick的字。实际上,我们不想遍历无限的位图索引。